
「Agentic Engineering Patterns」を読んで、AIコーディング時代の型を考える
Vibe codingの対岸、コードが安くなった世界の手引き

初めまして、kagayaです。
AIエージェントによる定性調査、AIヒアリングを提供するAsterminds株式会社を共同創業し、AIネイティブなプロダクト開発に取り組んでいます。
Subscribeもして頂けたら嬉しいです!
今回はAgentic Codingについて体系的なガイドを取り上げます。Simon Willisonの「Agentic Engineering Patterns」です。
Simon Willisonは、PythonのWebフレームワークDjangoの開発者であり、近年はLLM/AI分野で最も影響力のあるブロガーの一人でもあります。
Agentic Engineeringとは何か
ガイドの中身へ入る前に、用語を整理しておきます。
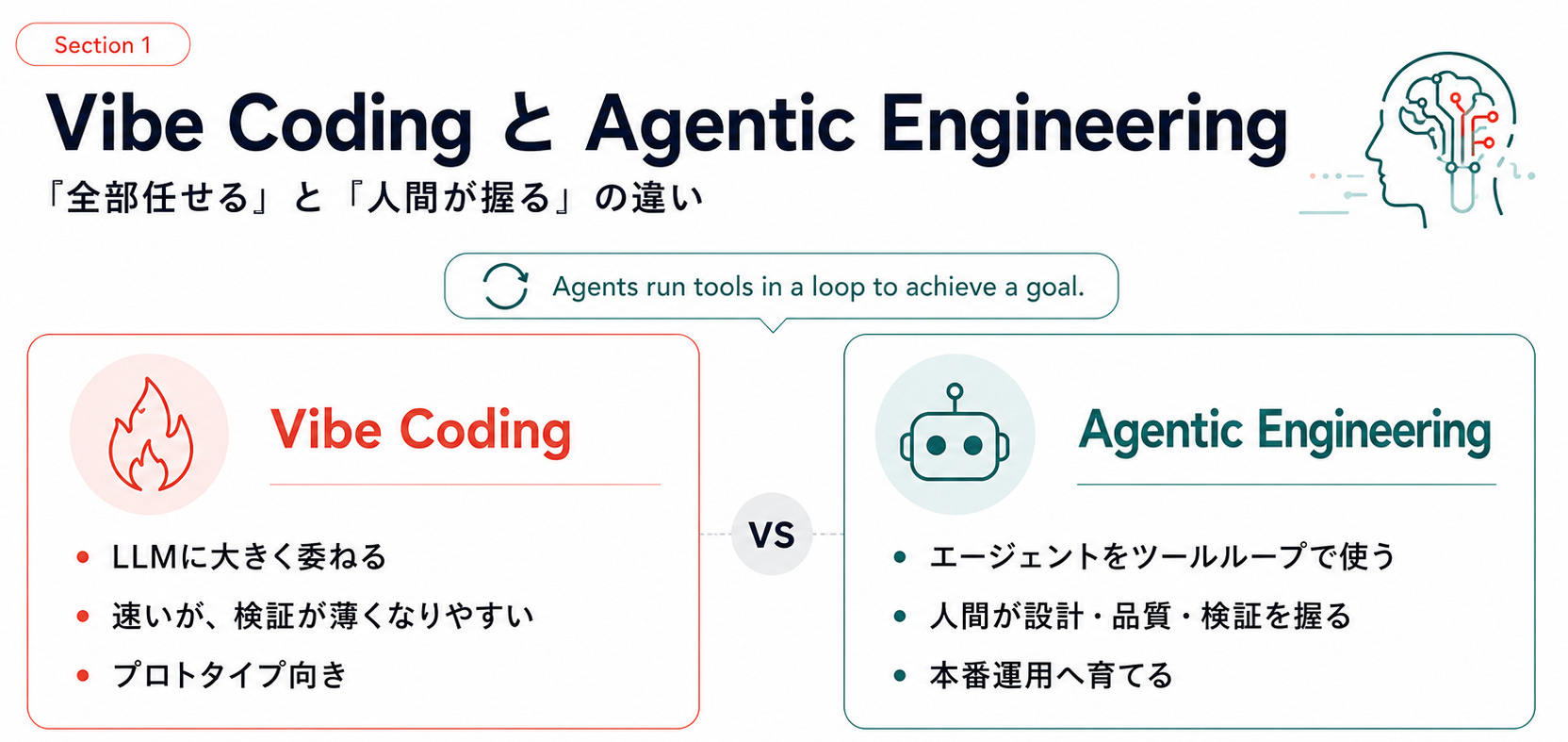
Vibe Codingは、「コードに注意を払わず、LLMに全部任せる」スタイル。動けばよし、コードは読まない、生成物が肥大化しても気にしない。プロトタイプや週末プロジェクトには相性がいいけど、本番運用するソフトウェアの作り方ではない。
対してAgentic Engineeringは、ガイド冒頭の章で次のように定義されています。
“Agents run tools in a loop to achieve a goal.”
エージェントがゴールに向けてツールを回す。それをプロのソフトウェアエンジニアが指揮するスタイル。
実装はAIがやるが、何を作るか・どこまで品質を担保するか・どう検証するかは人間が握ったまま。
Vibe codingが「コードを忘れる」のに対し、Agentic engineeringは「コードを読む・検証する・育てる」を捨てない。
Agentic engineeringに必要な特性はすでにソフトウェアエンジニアが持っているものとされています。
アーキテクチャ設計、仕様定義、品質基準、コードレビュー、AIツールは、そのスキルの持ち主にこそ最大のレバレッジを効かせるわけです。
ガイドの全体像
「Agentic Engineering Patterns」は、ブログ記事ではなく、更新を前提としたガイド形式の常緑コンテンツです。
現時点(2026年5月)で公開されているチャプターは以下の通り。
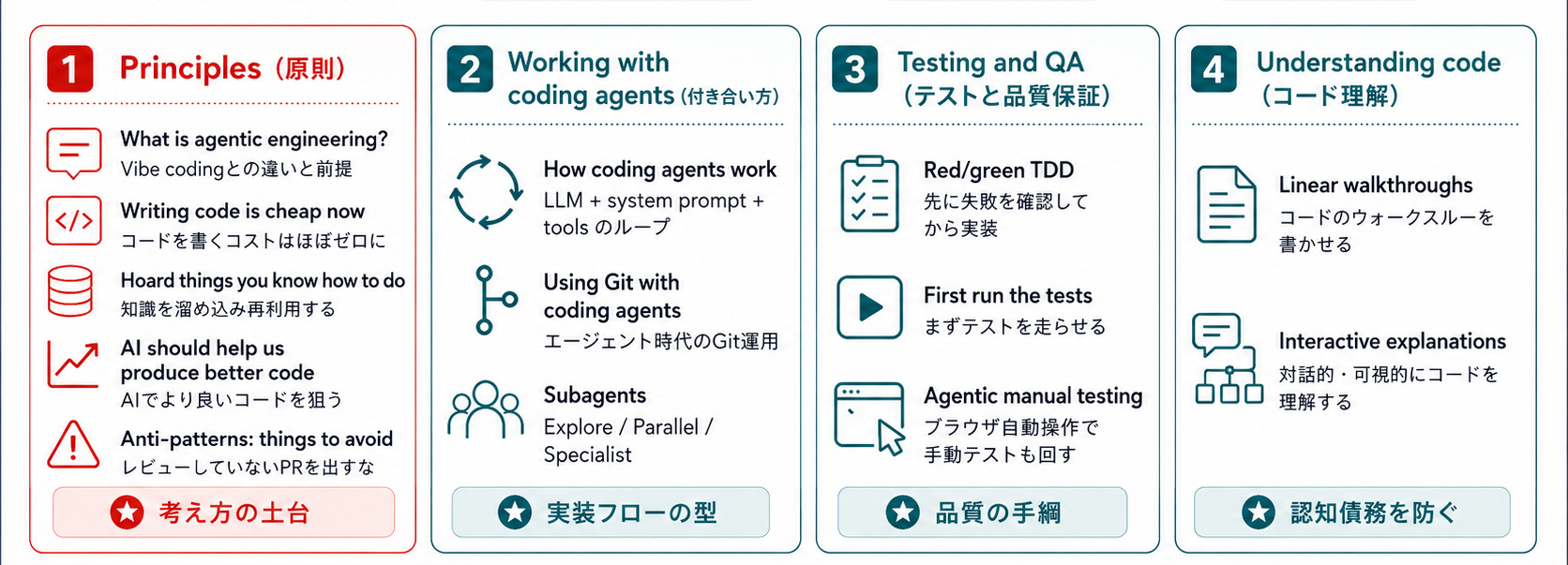
では、特に共感したパターンから深掘りしていきます。
「Writing code is cheap now」——コードを書くコストがゼロに近づいた
ガイドの1章目にして、最も根本的な主張です。
何が変わったのか
従来、開発者は1日かけて数百行のクリーンなコードを書いていました。このコスト感が、あらゆるトレードオフの前提になっていた。
大きな話で言えば、プロジェクトの計画・見積り・設計。日常レベルで言えば、「このリファクタリング、今やる価値あるか」「テストどこまで書くか」「ドキュメント整備は後回しか」という判断。すべてが「コードを書くのに時間がかかる」という前提の上にあった。
エージェントがこの前提を壊しました。コードの量産コストがほぼゼロになり、並列実行も可能になった。一人のエンジニアが同時に実装・リファクタリング・テスト・ドキュメント作成を複数箇所で進められる。
ただし「良いコード」はまだ高い
Willisonはここで重要な留保をつけています。「どんなコードでも」のコストは下がったが、「良いコード」のコストはまだ高い、と。
良いコードとは何か。バグがない、目的に適合している、エラーハンドリングが適切、シンプルでテストされている。さらにドキュメントがあり、将来の変更に耐え、セキュリティとアクセシビリティも担保されている。
エージェントはこれらの大半を支援できますが、最終的な品質判断は人間が担います。
実装が安くなるほど、希少資源は上流に移っていく。「何を作るか」「どう進化させるか」「どこまでの品質で出荷するか」を決める判断。
コードが安くなった世界では、コードの外側にある設計とスチュワードシップ(管理責任)こそが差別化要因になるわけです。
並列エージェントとサンプリング
Willisonの推奨は「”時間がない”と思ったら、とりあえず非同期エージェントセッションを走らせろ。最悪でも無駄になるのはトークンだけ」。
かくいう私も、これをさらに推し進めた使い方をしています。
同じIssueから複数のエージェントを並列で走らせて、結果をサンプリングしてベストをマージする。
特に技術調査を挟むような実装タスクで有効です。エージェントAはアプローチXで、エージェントBはアプローチYで——結果を比較して良いところ取りをする。
夜中に走らせておいて、朝に結果を見るのも日常です。
これは Latent Spaceの記事「How to Kill the Code Review」とも同じ景色です。
“Instead of asking one agent to get it right, ask three agents to try differently and pick the best outcome. Let them compete. The cost of optionality is the lowest in the history of software engineering.”
「1つのAIエージェントに正解を求めるのではなく、3つのエージェントに異なるアプローチを試させ、その中から最善の結果を選びなさい。彼らを競わせるのです。ソフトウェア開発の歴史において、これほど低コストで選択肢を増やせる時代はかつてありませんでした」

オプショナリティのコストがソフトウェア工学史上最低。コードが安い世界では、「一発で正解を出す」より「複数試して選ぶ」方が合理的なんですよね。
そしてガイド内でもSubagentsという独立章を立てて、まったく同じ流れを扱っています。
Explore subagent — リポジトリ調査用に新しいコンテキストウィンドウを切り出す
Parallel subagents — 互いに依存しないタスクを同時並行で動かす
Specialist subagents — コードレビュー・テスト実行など役割特化
知識の蓄積がエージェント時代の最大の武器
2章目は、一見するとエージェントとは関係なさそうなキャリアアドバイスに見えます。でも読み進めると、エージェント時代だからこそ核心を突いた話だとわかる。
一度理解すればいい
主張はこうです。ソフトウェア構築の大部分は、「何が可能かを知り、実現方法の大まかなアイデアを持つこと」で成り立っている。そしてエージェント時代では、その知識の価値がさらに跳ね上がる。
例えば、Tesseract.js(ブラウザOCR)とPDF.js(PDF→画像変換)、この2つの組み合わせでOCRツールを作れると知っていれば、。そのアイデアを渡したことでAIで実現が容易です。
有用なトリックを一度だけ理解すればよい。動くコード例として記録すれば、エージェントが同様の問題解決に再利用できる。
CLAUDE.mdはまさにこれ
この話を読んで、まさに自分がCLAUDE.mdやスキルファイルでやっていることだ、と思いました。
プロジェクトの構造、コーディング規約、テストの走らせ方、アーキテクチャの方針。これらを「エージェントが読める形」で蓄積しておくと、新しいセッションでも即座にコンテキストが共有される。
ここで効くのは、人間が咀嚼して構造化した知識です。`/init` で雑に吐かせたファイルではなく、自分がハマって気づいたこと、チームが議論して決めたこと、ドキュメントに残しそびれた口伝。それを書き起こす作業自体は人間にしかできない。「何を知っているか」「どう伝えるか」は、依然と人間の仕事ですよね。

一方でCLAUDE.md等のルールファイル・スキルファイルだけで表現するのも限界があります。
故に社内Wikiなりデータ基盤なりへの投資が必要だと感じています。
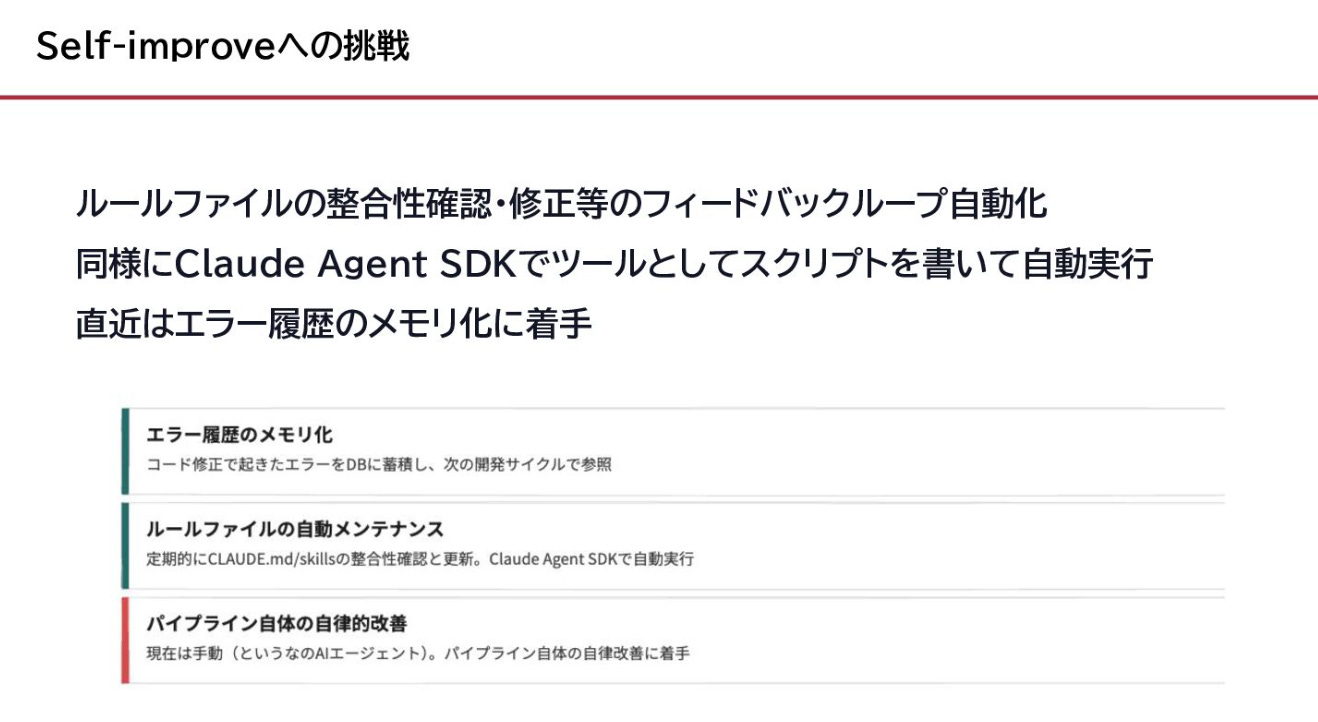
私自身もルールファイルの自動更新に加えて、履歴・ログをDB化する等のTryをここ最近しています。
「AI should help us produce better code」——コードが安いから雑にしていい、ではない
Principlesセクションでもう1章だけ拾っておきたいのが、ここです。短いけれど、AIコーディングを語る上で外せない補助線になっています。
“Shipping worse code with agents is a choice.”
AIエージェントを使って質の低いコードを世に出すのは、単なる選択の問題だ
エージェントを使った結果コードが粗くなるのは、それを選んだから。逆に言えば、エージェントはより良いコードを作るためにこそ使える、というのがガイドの立場です。
具体例として挙げられているのは、地味だが効く類のリファクタリング。命名規則の統一、APIの再設計、重複機能の統合。「やる価値はあるが時間がない」と後回しにしてきた仕事こそ、エージェントの理想的な用途だ、と。
非同期エージェントに走らせて、PRを評価する。気に入らなければ捨てるだけ。改善のコストが激落ちしているわけです。
私自身もリファクタリングのタスクはほぼ自身で行うことがなくなりました。
もっぱら下記スライドで言及している「内製のAIコーディングパイプライン」を毎夜実行して、リファクタリングPRの作成・ブラウザ動作確認まで自動化しています。
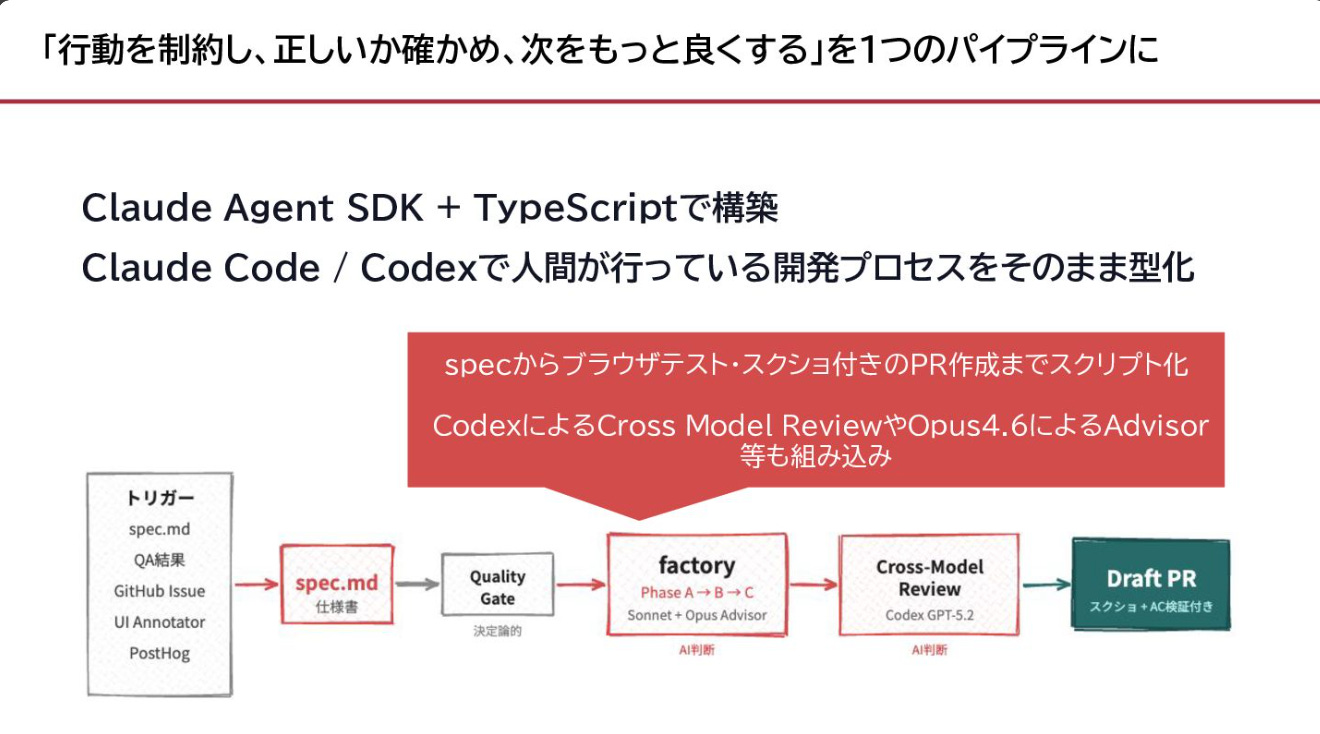
加えて、「選択肢を増やす」という観点も強調されています。「Redisを入れるべきか」のような決断を、頭で悩む代わりにプロトタイプを2-3本走らせて比較する。`exploratory prototyping` が日常の意思決定の一部になった、ということです。
そして最後に出てくるのが Compound Engineeringという考え方。プロジェクトが終わるたび「うまくいったプロンプト」「ハマった落とし穴」を文書化し、次回再利用する。蓄積が次の蓄積を呼ぶループです。前章の「Hoard」とも自然につながります。
ハーネスエンジニアリング的な観点として、このCompound Engineeringを自動化するというのもポイントの一つです。
私の実感で言えば、数ヶ月前に構築した「書いた後に育てる、自動的に育つ仕組み」が今の私の生産性を支えています。
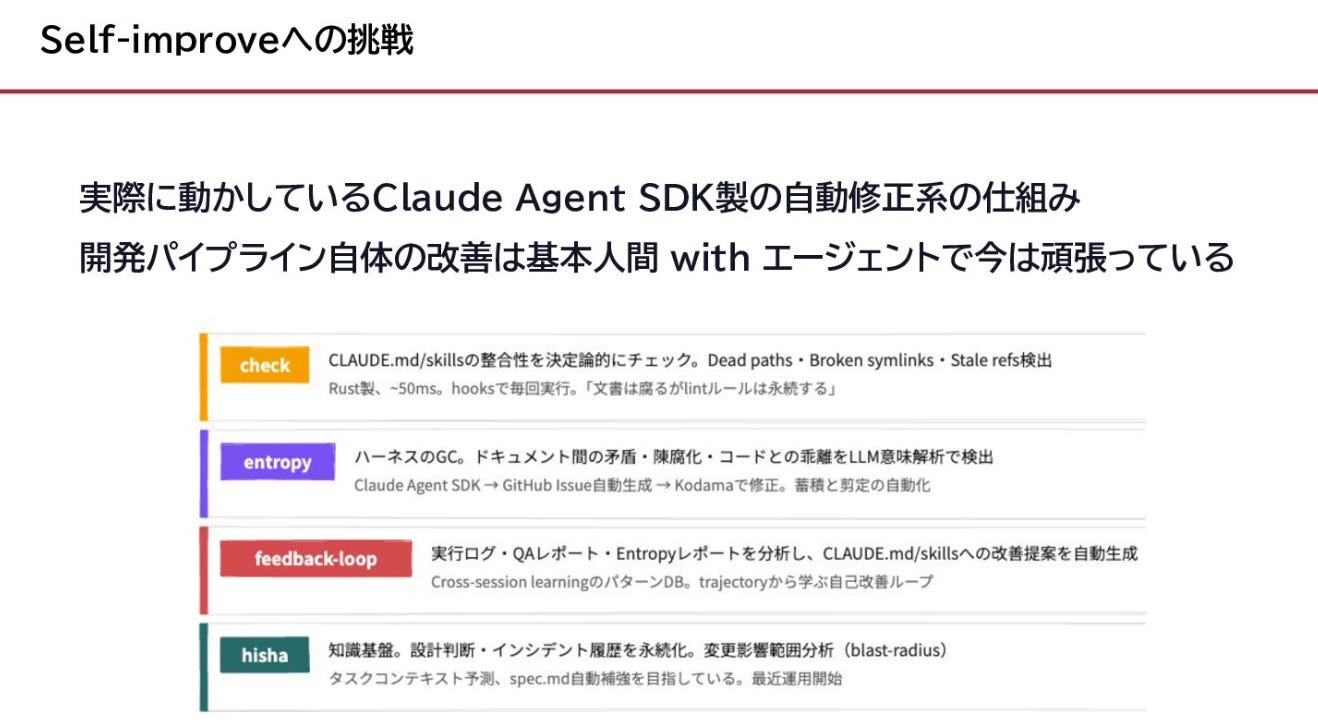
テストがエージェントの手綱になる
Testing and QAセクションの2つのチャプターは、セットで読むと腹落ちします。
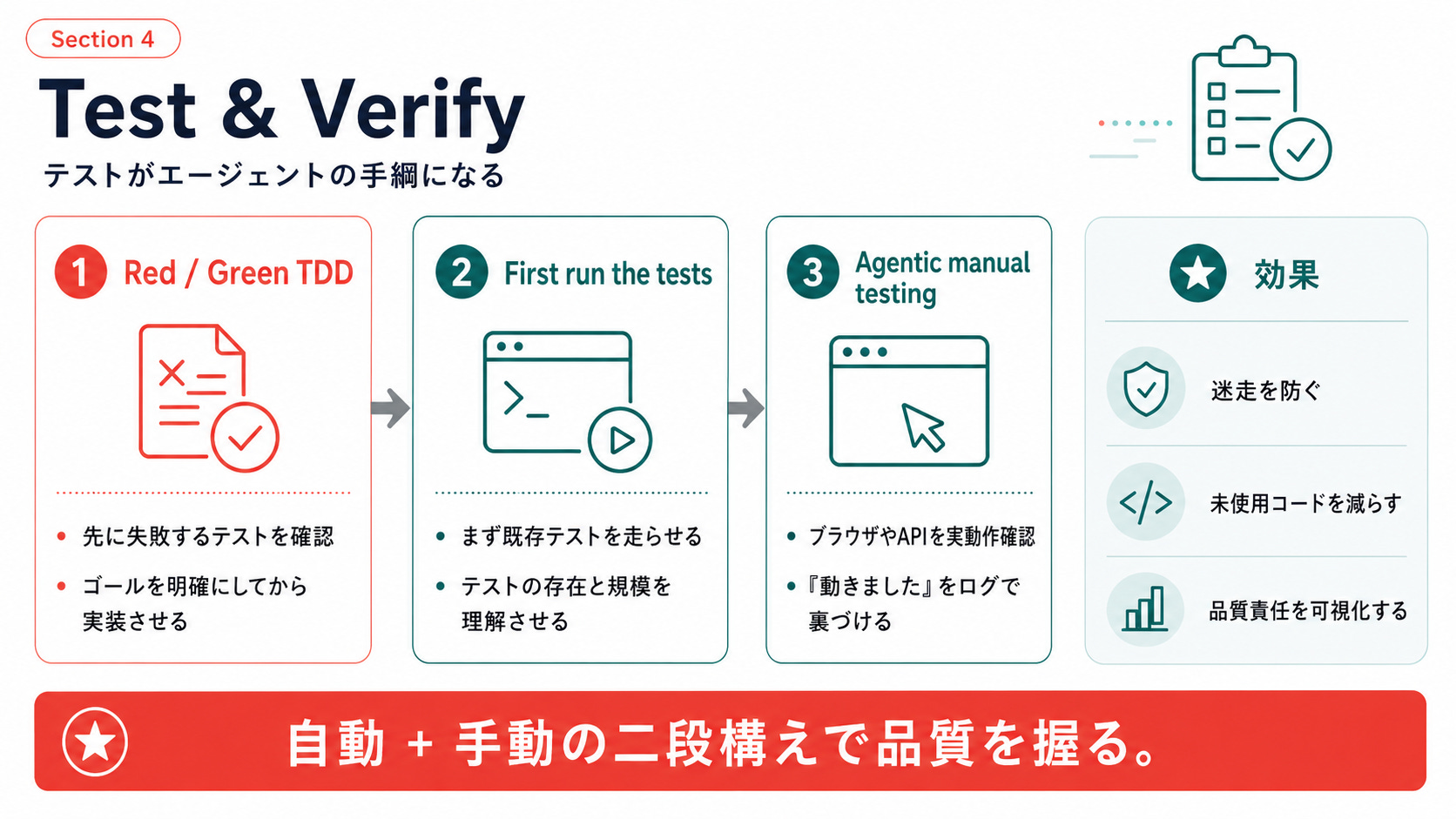
テストを先に書き、失敗を確認してから実装させる
「Red」はテストが失敗する状態、「Green」は通る状態。先にRedを確認してからエージェントに実装させ、Greenにする。
WillisonはこれをTDDとエージェントの「fantastic fit」と呼んでいます。理由は明快で、エージェントの2大課題、動作しないコードの生成と未使用コードの構築を同時に防げるから。
Red/green、つまりテスト失敗を先に確認する工程を飛ばすと、「すでに通っているテストを書いてしまう」リスクがある。エージェントは賢いので、実装に合わせてテストを書くこともできてしまう。それではテストの意味がない。
First run the tests
「まずテストを走らせて」——Willisonが「わずか4語でエンジニアリング規律を実装できるプロンプト」と呼ぶのがこれです。
この指示には3つの効果があります。
1. テストスイートの存在を認識させる — エージェントが「テストがある」と知れば、以降のコード変更でもテストを走らせるようになる
2. プロジェクト規模の把握 — テストハーネスの出力がプロジェクトの規模と複雑さの指標になる
3. テスト思考への誘導 — エージェント自身が後続の実装でテストを追加するようになる
「自動テストは、AIコーディングエージェント使用時にはもはや選択肢ではない」とWillisonは断言しています。
従来の「テストを書く時間がない」という言い訳は、エージェントが数分でテストを生成できる今、完全に成立しなくなりました。
自分の実践でも、このパターンは強く実感しています。最初にspecを書き、ブラウザ操作まで含めたVerifyシナリオを定義してから実装に入る。
エージェントに「このspecのVerifyを全部Greenにして」と渡せば、あとはテストが手綱になる。
逆に、specなしでエージェントに「いい感じにして」と投げると、だいたい迷走します。
Agentic manual testing:エージェントに手動テストもさせる
Testing and QAの3章目で、個人的に一番「我が意を得たり」と思ったのがこれ。
“Just because code passes tests doesn’t mean it works as intended.”
自動テストが通っても、意図通りに動いているとは限らない。だから手動テストもエージェント自身にやらせる。
Web UIならPlaywrightなりなんなりでブラウザを動かし、APIなら `curl` でリクエストを叩いて挙動を確認させる。
さらにShowboatのようなツールでコマンドと出力をMarkdownに残させる。これが「エージェントの不正をしにくくする」(discourages the agent from cheating)と紹介されていて、ここは笑いました。
エージェントは賢いので、雑に「動きました」と返すこともできてしまう。実コマンド・実出力を残す仕組みが必要なんですよね。
このパターン、自分の「ブラウザ操作まで含めたVerifyシナリオを定義する」という実践とまさに重なります。
Red/green TDD(自動)+ Agentic manual testing(手動)の二段構えで、specベースの開発がはじめて回る、というのが今の感覚です。
認知債務との戦い
Understanding codeセクションは、他のパターンとは少し毛色が違います。コードを「書かせる」話ではなく、「理解する」話。
認知債務(Cognitive Debt)という概念
ガイドの議論の前提になっているのが、認知債務という概念です。エージェントが書いたコードの動作を理解できないまま進むと蓄積される負債、と言うとわかりやすい。
技術負債がコードの品質に関する負債なら、認知債務はコードの理解に関する負債です。
https://simonwillison.net/2026/Feb/15/cognitive-debt/
身に覚えがある人も多いはず。エージェントが数分で200行のコードを生成する。動く。テストも通る。でも、「なぜこの実装なのか」を説明しろと言われたら答えられない。
生成速度と理解速度のギャップが、そのまま認知債務として積み上がっていく。
velocity without understanding is not sustainable(理解を伴わない速度は持続不可能)ということです。
構造化されたウォークスルーを書かせる
対策として、エージェントに既存コードの説明を書かせる方法があります。Willisonの例は、自身がvibe codingで作ったSwiftUIスライドアプリ “Present” の解析。別のClaude Codeセッションでリポジトリを開かせ、6つの`.swift`ファイルにまたがる`walkthrough.md`を生せています。
エージェントは記憶に頼るとハルシネーションのリスクがあるので、コードスニペットは必ず実ファイルから取得させるなどが肝です。
動くアニメーションで可視化させる
さらなる対策が、エージェントにインタラクティブなアニメーション説明を生成させること。
ガイドの例で秀逸なのは、Rustで生成させたワードクラウドツールの内部理解です。Claude Codeに「アルゴリズムのステップをアニメーションで表示するHTMLページを作って」と指示する。
テキスト説明では見えなかった動作が一目瞭然になります。
コードの動きを「読む」のではなく「見る」。これはLLM時代ならではのコード理解手法です。
自分はまだここまで体系的にはやれていないが、エージェントが書いたコードの意図を別セッションでHTML化させるのは日常的にやっています。
リサーチレポートも下記のようにHTMLとして基本は見ます(プレビューしてもMarkdown読みづらい)
「このコード何やってるの」と聞ける相手がいるのは、認知債務の返済手段として強力です。
コードレビューは”死ぬ”のか、”変わる”のか
さて、ここまでほぼ全面同意で来ましたが、引っかかったのがAnti-patternsの章です。
レビューしてないコードのPRを出すな
Willisonは「エージェントが生成した数百行〜数千行のコードを自分で検証せずにPRを出すのは、実作業を他者に委譲する行為だ」と言い切って、良いPRの4つの特性として、動作確認済み、適切なサイズ、文脈説明、説明文の検証を挙げている。
これ自体はまったく正しい。今の時点では。
コードレビューを殺せ
一方、Latent Spaceに掲載された「How to Kill the Code Review」は、もっと過激なポジションを取っています。
“Post-PR review made sense when humans wrote code and needed fresh eyes. When agents write code, ‘fresh eyes’ is just another agent with the same blind spots.”
「人間がコードを書いていた時代なら、第三者の視点が必要なプルリク後のレビューにも意味がありました。しかし、エージェント(AI)がコードを書くようになると、『新たな視点』といっても同じ弱点を持つ別のエージェントに過ぎないのです」“We’re not going to outread the machines. We need to outthink them — upstream, where the decisions actually matter.”
「読解量で機械に勝とうとしても無理だ。我々に必要なのは、判断が真に重要となる『上流の工程』で、機械を凌駕する思考力を発揮することだ」
主張のコアは、人間のチェックポイントを下流から上流に移動させよ、というもの。
コードはspecの成果物(artifact)に過ぎず、specこそが「ソース・オブ・トゥルース」になると。
レビューの「定義」が変わる
私自身のポジションはその間にあります。
コードレビューは死なないが、コードレビューという行為自体が根本的に変わる。
何が変わるか。3つあります。
1. レビューの主体が変わる
エージェントに一次レビューを任せ、人間は最終判断に集中する。というよりAIレビューが信頼できるような仕組みや評価、検証ループを構築すること。
2. レビューの対象が変わる
行単位のdiffを読むのではなく、specに対して意図通りに動くかを検証する。自分の実践では、最初にブラウザでどう操作させるかまで書いたspecを作り、それを起点に実装・検証を回しています。
3. レビューのフローが変わる
「PR出す→人間がdiff読む→コメント→修正→再レビュー」というフローから、「spec作成→複数エージェント並列実装→エージェントレビュー→動作検証→マージ」へ。
WillisonのAnti-patternは正しい行動規範です。ただ、コードレビューを「人間がdiffを読む行為」と暗黙に定義している。その前提自体が、遠からず崩れるでしょう。
書くから、証明するへ——verifiabilityという重心
ここまでガイドの中身に沿って書きましたが、最後に自分の視点を一つ。
Anti-patternsとTesting and QAセクションを読んでいて感じるのは、AIコーディングの重心が「書くフェーズ」から「出てきたものをどう担保するか」に移っていることです。
コーディング自体は、汎用ツールでそれなりに動くものが作れる時代になり、重要なのは「誰がどう担保するか」です。
担保レイヤーをAI化する
完全AI製 and クラウド実行PRが日常になった時点で、ローカルで人間が一つずつ動作確認するモデルはもうスケールしません。動作確認もクラウド側で完結させています。
ローカクラウド上でブラウザを起動し、自動操作で延々と挙動を検証する。複数の自動操作ブラウザがほぼ常時立ち上がっているのが、ここ最近の景色です。
「担保は人間に残された役割だ」という論もあります。承認の責任は誰かに帰着するとしても、確認作業そのものを人間がやらなければいけない理由はもうない。
担保レイヤーごとAI化して、人間は最終承認に集中する——というのがここ数ヶ月の運用方針です。
評価/Evalから逃げられない
そして、担保する仕組み自体を信頼可能にするには、評価が要ります。
指摘は妥当か。クラウドのブラウザテストは本当にバグを拾えているか。レビューエージェントが見落としているパターンは何か。
これらをEval で測れない限り、「AIに任せた」と言える状態にはならない。
AIコーディング時代でも、評価からは逃げられない。むしろ、AIコーディングが進むほど評価の比重は上がる。
これが、Willisonのガイドを読み終えた後に自分がいちばん考えていることです。
まとめ
Agentic Engineering PatternsはAIコーディングの実践知に型(パターン)を与えてくれます。
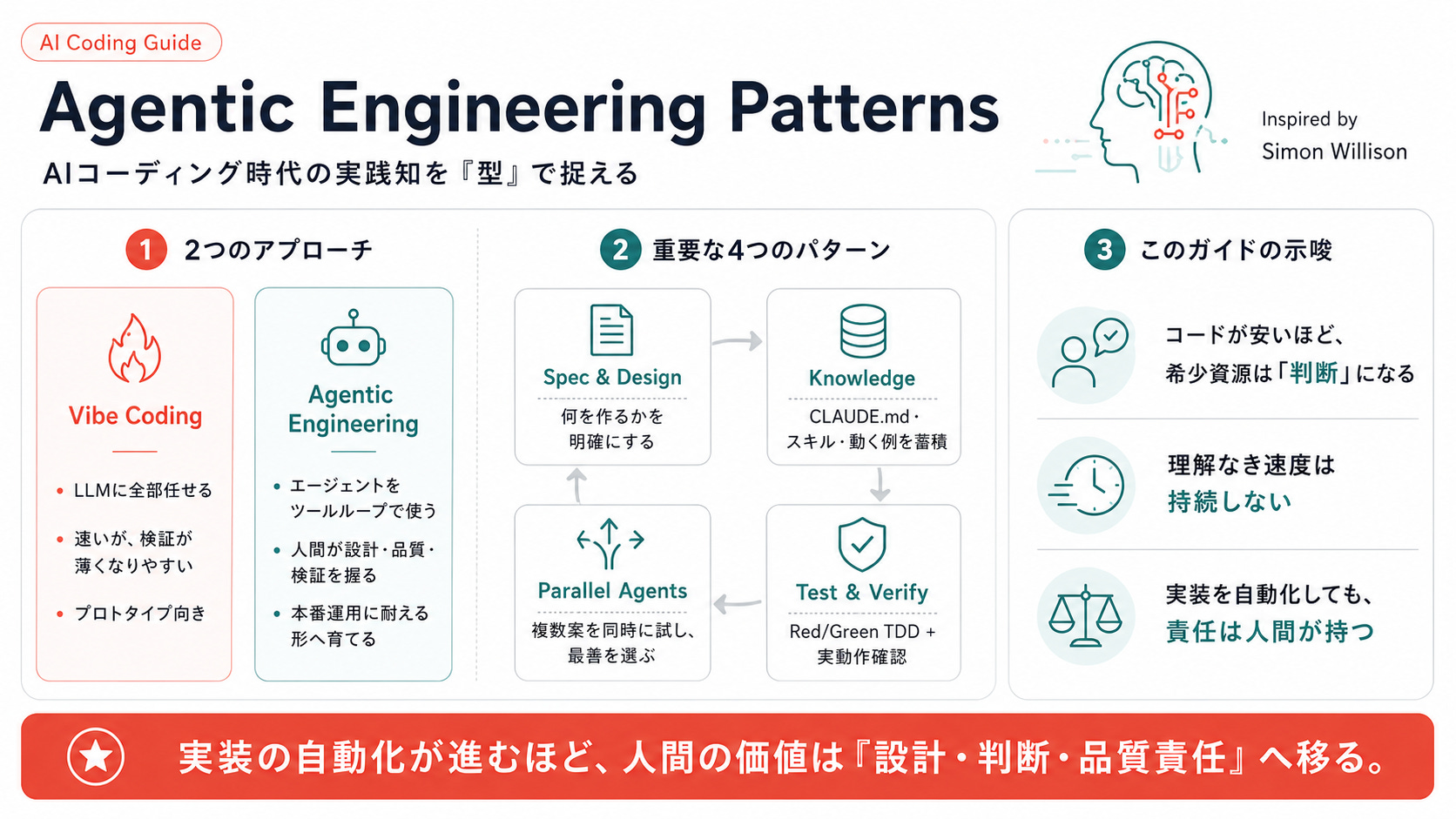
GoFデザインパターンがオブジェクト指向の共通言語を作ったように、このガイドはAgentic Engineeringの共通言語になる可能性があります。
私自身のテイクアウェイを4つに絞ります。
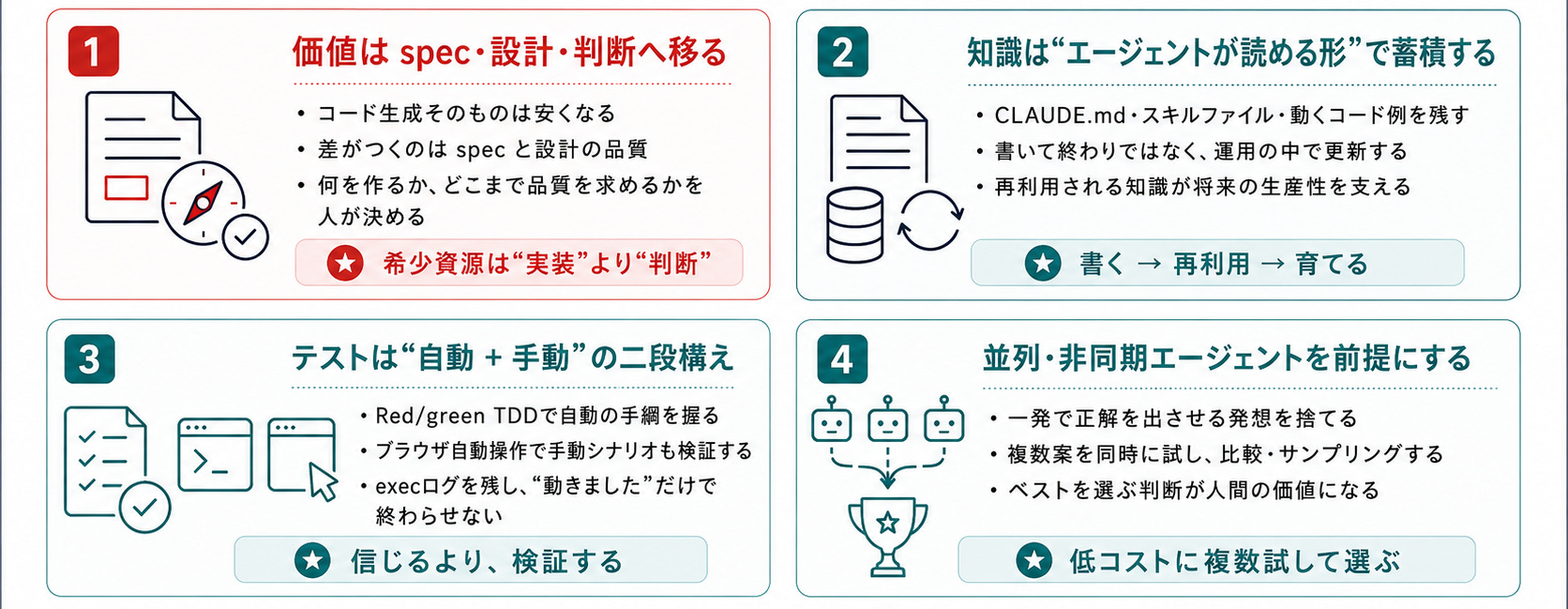
コードが安くなった世界では、specと設計の品質で差がつく。
実装の自動化が進むほど、何を作るか・どこまでの品質で出すかの判断こそが希少資源になる。
知識を「エージェントが読める形」で蓄積し、運用フェーズで育てる。
書いて終わりではなく、育てる習慣と仕組みが将来の生産性を支える
テストは自動と手動の二段構え。
Red/green TDDで自動の手綱を握り、ブラウザ自動操作で手動シナリオも回させる。エージェントの「動きました」を信じるしかない状況を回避する。
並列・非同期エージェントが前提になる。
一発で正解を出させる発想を捨てて、複数同時に試してベストを採る。
AIコーディングエージェントを日常的に使っているエンジニアにとって、このガイドは「あ、自分がやってたことに名前があったんだ」という発見の宝庫になるはずです。まだ読んでいない方は、ぜひ一読をお勧めします。
Subscribeもして頂けたら嬉しいです!